April 5, 2026
Why AI Doesn’t Just Find Answers — It Builds Them
Note on methodology: The vocabulary in this article was developed through iterative research conversations between the author and AI agents across multiple research cycles, then stress-tested against existing NLP and ML literature. Many concepts map to documented phenomena. Some are original hypotheses without empirical validation. All are published here as working tools — named, described, and su

Note on methodology: The vocabulary in this article was developed through iterative research conversations between the author and AI agents across multiple research cycles, then stress-tested against existing NLP and ML literature. Many concepts map to documented phenomena. Some are original hypotheses without empirical validation. All are published here as working tools — named, described, and submitted for challenge. Where a concept is speculative, this article says so.
Most of the advice circulating about AI search optimization treats AI systems the way we used to treat Google circa 2015: as a retrieval machine you feed keywords to. Get the right words on the page, earn the right links, wait for the algorithm to find you.
That model was always a simplification. For AI-powered search, it’s almost entirely wrong.
When ChatGPT, Claude, Perplexity, or Google AI Overviews responds to a query, it isn’t fetching a document from a database. It’s constructing a response — building an architecture of information that holds together logically, reads coherently, and resolves the user’s uncertainty as efficiently as possible. The system isn’t asking “what is the most popular answer?” It’s asking something closer to “what is the most stable answer I can build right now?”
That distinction changes everything about how you think about content strategy.
I’ve been developing a vocabulary for describing what’s actually happening when AI systems evaluate, weight, and prune information during response generation. Some of what follows is grounded in well-documented research. Some is original hypothesis. All of it is useful — I know because I’ve been applying it to our own content program at Xponent21, watching what happens when we do the work consistently and what happens when we don’t.
This is a working vocabulary, not a finished theory. I’m publishing it because naming things precisely is how you start solving them — and because I’d rather have practitioners and researchers challenge these concepts in public than have them calcify unchallenged in private.
## The Central Problem: AI Builds, It Doesn’t Retrieve
Traditional search was retrieval: index documents, match queries to documents, rank by authority and relevance. Your job as a content creator was to be in the index and rank well. The system was a very sophisticated librarian.
Generative AI search is different. When a model constructs a response, it is performing what I’m calling Structural Resilience Optimization — the process of collapsing a high-dimensional probability space into the most coherent, stable output possible given the constraints of the query. The model isn’t locating the best answer. It’s building the most structurally sound answer it can produce.
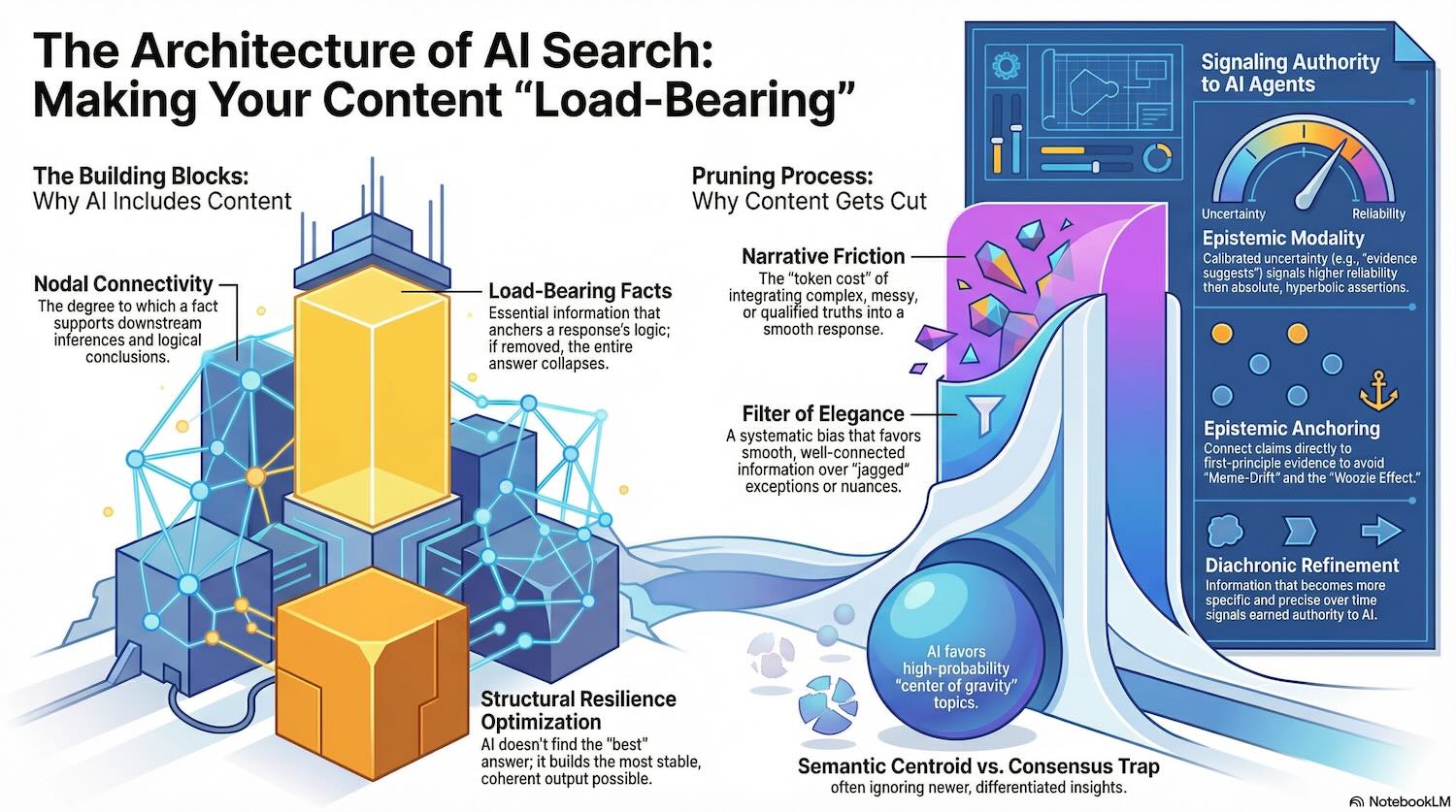
Think of it as architecture rather than retrieval. A response is a building. Every piece of information is a load-bearing element or it isn’t. The model’s implicit question at every step is: does this piece of information support the structure, or does it destabilize it?
This framing — the model as architect rather than librarian — is the lens through which everything else in this vocabulary makes sense.
### **What Makes Information “Load-Bearing”**
If you want your content to be cited by AI systems, the single most important question to ask about any piece of information is: would the response collapse without it?
Information that passes this test I’m calling a Load-Bearing Fact. These are the pieces that anchor a response’s logical structure — the concepts other conclusions depend on, the data that frames the problem, the definitions that make the rest of the answer interpretable.
The mechanism behind this is Nodal Connectivity — the degree to which a piece of information supports downstream inferences. A fact with high nodal connectivity is one that, if removed, causes a cascade of logical problems throughout the response. A fact with low nodal connectivity is one the model can drop without anything falling apart.
Crucially, nodal connectivity is independent of accuracy. A fact can be entirely correct and still have low nodal connectivity if it doesn’t connect to anything else in the response architecture. This is why technically accurate content sometimes gets omitted from AI responses in favor of slightly less precise but more structurally useful information — the model is optimizing for coherence, not correctness in isolation.
The content strategy implication is direct: don’t just be accurate. Be structurally necessary. Write content that other conclusions depend on. Connect your specific claims to broader frameworks that give them context and weight.
### The Filter of Elegance — and Why “Messy” Truths Get Cut
Here’s the bias that most content creators don’t know they’re fighting.
AI models optimize simultaneously for structural coherence and linguistic flow. When a piece of information is technically correct but requires multiple qualifying sentences to fit cleanly into a response — when it’s counter-intuitive, narrowly applicable, or disrupts the rhetorical rhythm — it faces what I’m calling Narrative Friction: the token cost of integrating that fact without breaking the response’s coherence.
High narrative friction leads to omission. The model calculates something like a Utility-to-Token Ratio — does this information add enough value to justify the explanatory overhead it requires? If the answer is no, the fact gets pruned, even if it’s accurate.
The aggregate effect is what I call the Filter of Elegance: a systematic bias toward smooth, well-connected information and away from jagged, exceptional, or highly qualified truths. Information that fits cleanly into the established response architecture survives. Information that disrupts it gets cut.
For practitioners, this has a specific implication: counter-intuitive findings, important exceptions, and nuanced qualifications are the content most at risk of being filtered out. If your competitive advantage is in the nuance — if the thing that makes your expertise valuable is the exceptions you know about — you need to make that nuance structurally load-bearing, not just accurate.
One technique: lead with the exception, not the rule. If your content opens with the counter-intuitive finding and builds the conventional wisdom around it, the exception becomes the anchor. It has high nodal connectivity by design.
A related concept worth naming: Adverbial Inflation. Content that uses intensifiers and superlatives — “absolute,” “revolutionary,” “undeniably,” “game-changing” — correlates strongly with low-quality training subsets and acts as a reliability red flag. This is well-documented in NLP research on quality signals in training data. Strip the hyperbole. Confident, measured language signals authority. Loud language signals the opposite.
### **The Semantic Centroid and Why You Need to Be Near It**
Every topic, as an AI system understands it, has a center of gravity — the cluster of concepts, vocabulary, and framing the model associates most strongly with that subject. I’m calling this the Semantic Centroid.
Content that diverges significantly from the semantic centroid of its topic faces higher narrative friction by default. It’s not that the content is wrong — it’s that it exists at a greater distance from where the model’s probability space is densest, which means more structural work is required to integrate it.
This has two practical implications that point in opposite directions.
First, Semantic Consonance — using the vocabulary clusters associated with authoritative sources on your topic — helps your content get treated as credible by proximity. When your language matches the register and terminology of established sources in your space, you’re positioned closer to the semantic centroid, which reduces friction and improves inclusion probability.
Second, the semantic centroid is also a trap. I call it the Consensus Trap: the pull toward well-established, widely-repeated information at the expense of newer, more precise, or differentiated insights. If your competitive advantage is in being ahead of the consensus, you’re always working against the centroid.
The strategic move is to connect your differentiated insight to established load-bearing concepts before diverging from the consensus. Anchor first, then move. A new finding that opens by referencing an established framework has much better structural odds than one that opens by challenging it.
### How AI Evaluates Authority — and What Actually Signals It
One of the most consequential misunderstandings in AI search optimization is the assumption that authority works the way it did in traditional SEO: links, domain rating, page rank.
AI systems don’t read your domain authority score. They read the texture of your content.
Epistemic Modality describes the degree to which content acknowledges uncertainty and frames claims conditionally. Content that uses hedged language — “research suggests,” “evidence indicates,” “under specific conditions” — paradoxically scores higher for reliability than content that makes identical claims in absolute terms. Calibrated uncertainty is a marker of methodological awareness, which is strongly associated with authoritative sources in training data.
The inverse is also true. The Hallucination of Authority describes content that mimics the structural signals of expertise — formal language, citations, hedged phrasing — without the underlying logical coherence. Surface signals matter, but they don’t override structural integrity. If your citations don’t connect to your claims, the model registers the gap.
The most reliable authority signal is Diachronic Refinement — information that has become more specific and precise over time across multiple independent sources, rather than just being repeated. A claim that appeared as a general observation in 2022 and has since been narrowed, qualified, and validated across multiple domains is weighted very differently from a claim repeated at the same level of specificity for years without gaining methodological depth.
### The Woozle Effect and Consensus Density
The Woozle Effect — named after a pattern in Winnie-the-Pooh where characters follow their own footprints believing they’re tracking something new — describes a real and documented phenomenon: a claim achieves the appearance of consensus through wide repetition across derivative sources, despite tracing back to a single original assertion.
AI systems trained on large datasets are structurally susceptible to this. A claim repeated ten thousand times across blog posts, LinkedIn articles, and news aggregators creates a deep groove in the probability space — even if all ten thousand instances trace back to a single study that has since been challenged or superseded.
The distinction I’m drawing is between Consensus Density — the volume and diversity of genuinely independent sources supporting a claim — and Meme-Drift: information that survives through cultural repetition rather than methodological validation. High volume from derivative sources produces low effective consensus density.
Content that traces back to first principles — that shows its work, cites primary sources, demonstrates a path from evidence to conclusion — is weighted differently from content that simply repeats what everyone else is saying. I’m calling this Epistemic Anchoring: connecting your claims to first-principle evidence with a short, direct path.
This is why original research and first-person case studies have outsized authority in AI search. They’re genuinely independent sources. They resist meme-drift by definition.
Our own experience at Xponent21 is a direct example. The data from our visibility collapse — from over 90,000 daily impressions to under 9,000 in a single quarter when we let our own content program go ad hoc — isn’t a piece of information that exists anywhere else. It can’t meme-drift because it has only one source. That makes it a high-density epistemic anchor. The article documenting it is already earning citations for exactly that reason.
### The Shadow Query — What AI Is Actually Answering
When a model receives a query, it doesn’t just answer what was asked. It calculates the question the user should have asked if they had slightly more domain expertise — what I’m calling the Shadow Query. Then it answers both, with the shadow query often taking precedence.
A related pattern: the XY Problem, well-documented in software engineering and directly applicable here. When a user asks for solution X to solve problem Y, but X is a poor approach to Y, a well-functioning AI system corrects the premise rather than answering the literal question. It prioritizes the user’s underlying goal over their stated request.
Both patterns matter for content strategy in a specific way: your content needs to answer not just the question your audience is asking, but the question they should be asking. Epistemic Gap Analysis — the model’s process of identifying foundational knowledge the user didn’t request but needs to actually use the answer — means that content which provides prerequisite context alongside its primary answer has higher structural value than content that answers the question in isolation.
The practical move is to build this explicitly into your content structure. Before your primary answer, identify and address the foundational assumption the question rests on. This isn’t padding — it’s load-bearing scaffolding.
### **The Bias You Can’t Optimize Your Way Out Of**
Western Institutional Gravity describes the structural bias in most major LLMs toward English-language, Western-sourced training data. Western academic, governmental, and professional sources have higher representation and more formal interconnectedness in training datasets, which gives content resembling these sources a structural advantage — it sits closer to the semantic centroid of most topics by default.
The implication isn’t that non-Western sources are excluded. It’s that they face a higher structural burden to achieve the same inclusion probability.
For Western practitioners, the honest implication is that some of your authority comes from proximity to the centroid rather than from the quality of your work. That’s worth knowing — both for humility and for strategy. Actively citing and connecting to diverse sources isn’t just ethically correct, it’s structurally differentiating.
## **The Complete Working Vocabulary**
- **Structural Resilience Optimization** — The process by which AI response generation minimizes internal contradiction while maximizing the density of high-utility, logically anchored information. - **Load-Bearing Facts** — Information that anchors a response’s logical structure. Its removal would cause downstream inference collapse. - **Nodal Connectivity** — The degree to which a piece of information supports downstream conclusions. High connectivity means other facts depend on it. - **Kinetic Utility** — Whether information actively moves a user from uncertainty to resolution, as opposed to being a static accurate fact that doesn’t advance understanding. - **Narrative Friction** — The token cost of integrating a piece of information into a coherent response. High friction correlates with elevated omission probability. - **Utility-to-Token Ratio** — The implicit efficiency metric governing inclusion: does this information add enough value to justify the space it occupies? - **Filter of Elegance** — The systematic bias toward smooth, well-connected information and away from jagged, exceptional, or highly qualified truths. - **Semantic Centroid** — The center of gravity of a topic as the AI understands it. Content diverging significantly from it faces higher integration friction. - **Semantic Consonance** — When content uses vocabulary clusters matching authoritative sources on the same topic, gaining credibility by proximity. - **Consensus Trap** — The pull toward well-established, widely-repeated information at the expense of newer or differentiated insights. - **Epistemic Modality** — The degree to which content acknowledges uncertainty and frames claims conditionally. Hedged language scores higher for reliability than absolute assertion. - **Adverbial Inflation** — The use of intensifiers and superlatives that correlate with low-quality training subsets and act as reliability red flags. - **Hallucination of Authority** — When content mimics structural signals of expertise without underlying logical coherence. - **Diachronic Refinement** — Information that has become more specific and precise over time across multiple independent sources. A marker of earned authority. - **Woozle Effect** — When a claim achieves apparent consensus through wide repetition despite tracing back to a single original source. - **Meme-Drift** — Information surviving through cultural repetition rather than methodological validation. - **Consensus Density** — The volume and diversity of genuinely independent sources agreeing on a claim. High volume from derivative sources yields low effective density. - **Epistemic Anchoring** — Connecting claims to first-principle evidence with a short, direct path rather than to the consensus of people who also connected to the consensus. - **Semantic Cul-de-Sac** — Content that appears frequently but exists in a closed loop, failing to connect to broader logical frameworks. - **Western Institutional Gravity** — The structural bias toward English-language, Western-sourced training data due to higher semantic density and formal interconnectedness. - **Shadow Query** — The question a user should have asked if they possessed more domain expertise. AI systems often answer this instead of, or alongside, the literal query. - **Epistemic Gap Analysis** — The model’s process of identifying foundational knowledge the user didn’t request but needs to actually use the answer. - **XY Problem** — When a user asks for solution X to solve problem Y, but X is the wrong approach — prompting premise correction over literal response. - **Temporal Decay** — The rate at which information loses relevance weight based on the domain’s rate of change.
## **What This Is — and What It Isn’t**
This vocabulary is a set of hypotheses, not a theory. Several concepts — Western Institutional Gravity, the Woozle Effect, Epistemic Modality, Adverbial Inflation — are well-supported by existing NLP and ML research under different names. Others — Narrative Friction, Kinetic Utility, the Filter of Elegance — are directionally plausible but unmeasured. A few — the specific mechanisms behind Structural Resilience Optimization — are speculative descriptions of observed behavior not yet explained from first principles.
I’m publishing this vocabulary now because naming things is the first step toward testing them. The practitioner community has direct access to data that academic researchers don’t: we can observe what gets cited and what doesn’t, what earns AI Overview placement and what gets excluded, what holds position and what drifts. That’s real-world evidence that could validate or falsify these concepts if anyone is systematic about collecting it.
If you’re doing this work and tracking results, I want to hear from you. If you’re an ML researcher and see a concept here that maps to existing literature I’ve missed, I want to know that. If you think one of these concepts is wrong — not just named differently, but actually incorrect as a description of how these systems behave — make the case.
A formal preprint is in development for submission to SSRN, framed explicitly as a hypothesis-stage framework paper. If you’re interested in collaborating on experimental design — particularly around measuring Narrative Friction through controlled prompt variation, or testing Epistemic Modality as an independent inclusion variable — reach out directly.
The goal is to replace this vocabulary with something more precise. The only way that happens is in public.
Will Melton is the CEO of [Xponent21](https://xponent21.com/), a Richmond, Virginia-based AI optimization and digital marketing agency. He is the founder of AI Ready RVA and an instructor at the University of Richmond. His work on AI search visibility has been cited across Google AI Overviews, Claude, ChatGPT, and Perplexity.
Published April 5, 2026. This article will be updated as concepts are validated, challenged, or superseded.
### Leave a Reply [Cancel reply](https://willmelton.com/why-ai-doesnt-just-find-answers-it-builds-them/\\#respond)
Your email address will not be published.Required fields are marked \\*
Comment \\*
Name \\*
Email \\*
Website
Save my name, email, and website in this browser for the next time I comment.
- [About Will Melton](https://willmelton.com/) - [Insights](https://willmelton.com/blog/) - [Quotes](https://willmelton.com/quotes/) - [Talks](https://willmelton.com/speaker-samples/) - [Book Will to Speak](https://willmelton.com/book-will/)